Adding undo/redo to kilo (and debugging memory usage)
I add a naive undo feature to kilo and then go on a detour to investigate memory usage.
1. The code
The code is on github. The important
context is that we have a couple of structs, editorConfig, which represents
the global state of our editor, and erow, which represents a row of text and
some associated data:
typedef struct erow {
int idx; // which row in the buffer it represents
int size; // the row length
char *chars; // the characters in the line
char *render; // the "rendered" characters in the line, where eg. \t will expand to spaces
int rsize; // the length of the "rendered" line
unsigned char *hl; // the highlight property of a character
int hl_open_comment; // whether this line is part of a multiline comment
} erow;
typedef struct editorConfig {
int cx, cy; // cursor position
int rx; // render index, as some chars are multi-width (eg. tabs)
int rowoff; // file offset
int coloff; // same as above
int screenrows; // size of the terminal
int screencols; // size of the terminal
int numrows; // size of the buffer
erow *row; // current row
int dirty; // is modified?
char *filename; // name of file linked to the buffer
char statusmsg[80]; // status message displayed on at bottom of buffer
time_t statusmsg_time; // how long ago status message was written, so we can make it disappear
struct editorSyntax *syntax; // the syntax rules that apply to the buffer
struct termios orig_termios; // the terminal state taken at startup; used to restore on exit
int mode; // vim-like normal/insert mode
} editorConfig;
2. The approach
A common undo solution is to store the user action, and then perform an equivalent reverse operation when the user presses "undo". For example, if the user inserts 5 characters at cursor position xy, we later may want to delete 5 characters at cursor position xy.
I wanted something more general though: this a toy editor and I'd like to be able to hack arbitrary features onto it without having to code a corresponding undo feature. I started with the easiest possible approach: just copy and restore all the global state. This could be done with relatively few changes:
3. Turn our editorConfig value into a pointer
The editor stores a global editorConfig in a variable E. This holds state
like the cursor position and pointers to the erows that make up the buffer. I
wanted to be able to swap this out for an older version, so I turned it into a
pointer that represents the current global state.
I also added undo and redo pointers to the E struct. This could be used to
link a linear branch of undo/redo states.
4. Write a history_push() function
…which uses malloc() and memcpy() to clone editorConfig and the erow
structs that make up all the global state.
I can then update E to be a pointer to the current state, and
set E->undo and E->undo->redo to point to the right versions of state based
on the undo history.
I added a keyboard handler so I could manually invoke history_push() to test it.
5. Add history_undo() and history_redo()
These functions just return the appropriate E->undo/redo values. I added
vim-compatible u and R keybindings to invoke these.
6. Behold:
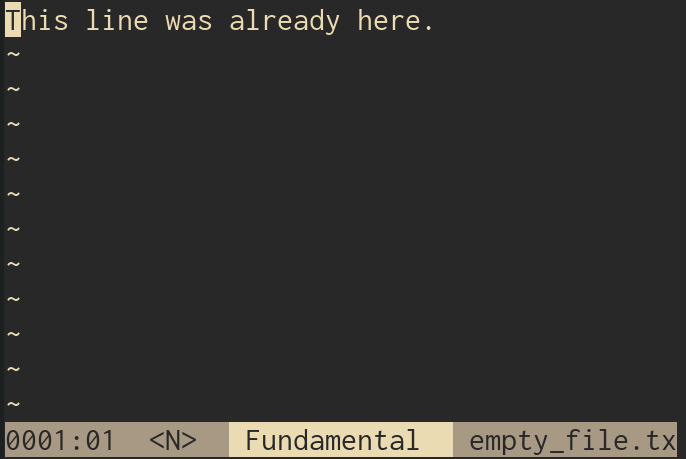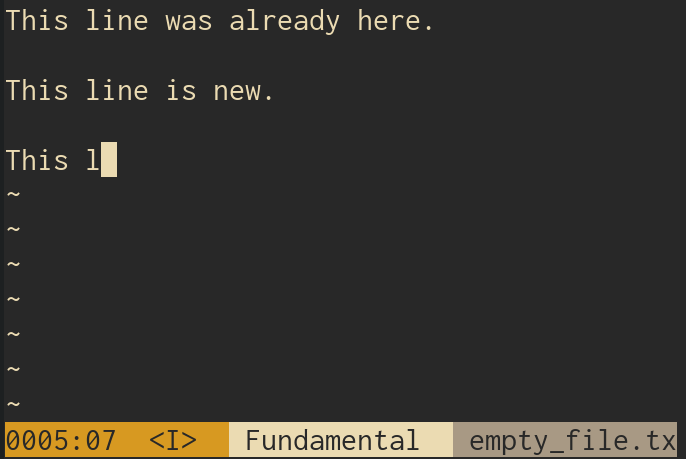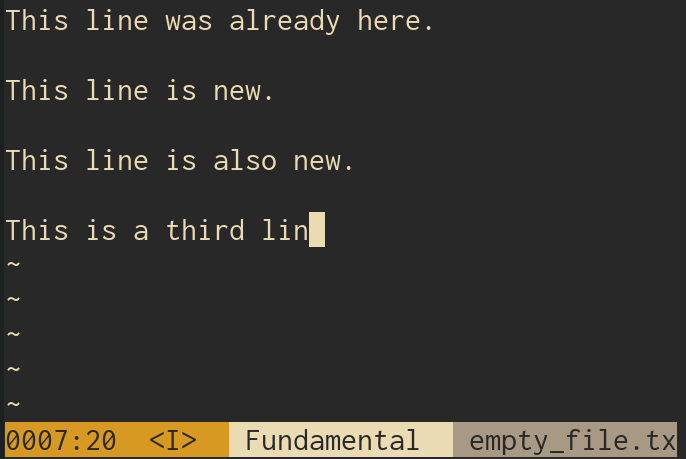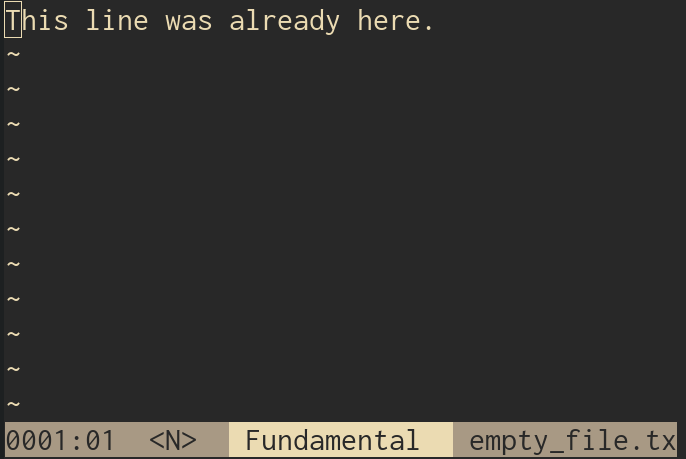
That's about it. We have an undo feature.
7. Job done?
I suspect not! My biggest concern is that this is surely very memory inefficient. Let's validate that.
8. Snapshotting process memory changes with pmap
I want to see how the editor's memory usage changes when I run my my
history_push() function. I'm sure there are heap-profiling or C-debugging
tools I can use to inspect state as it changes, but for speed I'm just going to
take some snapshots using pmap.
To see the delta in subsequent pmap calls we can write to a tempfile and
use diff:
#!/bin/bash
#
# pmap-diff.sh
#
# Snapshot the results of pmap to a file, then diff it on
# subsequent calls. Scope per PID.
ARG="$1"
if [ -z "$ARG" ]; then exit 1; fi
pidof "$ARG" || exit 1;
PROCESSPID="$(pidof $ARG)"
F="/tmp/pmap-$ARG.$PROCESSPID"
if [ ! -f "$F" ]; then
# pmap hasn't been called yet for this PID. Display the whole output.
pmap "$(pidof $ARG)" -x > "$F";
cat "$F";
exit 0;
else
# pmap has been called. Display the diff
mv "$F" "$F".previous;
pmap "$(pidof $ARG)" -x > "$F";
head -n 2 "$F";
diff "$F".previous "$F" && echo "no change";
rm "$F".previous;
fi
9. The test
I have an example text file that we can use for this. It's about 28.7KB:
$ wc kilo-org.c
1056 3826 28722 kilo-org.c
I open this file with the editor:
./kilo kilo-org.c
When I run ./pmap-diff.sh kilo for the first time, I see the full output of pmap:
Address Kbytes RSS Dirty Mode Mapping
00005652b5815000 8 8 0 r---- kilo
00005652b5817000 24 24 0 r-x-- kilo
00005652b581d000 8 8 0 r---- kilo
00005652b581f000 4 4 4 r---- kilo
00005652b5820000 4 4 4 rw--- kilo
00005652b67a1000 288 216 216 rw--- [ anon ] // this is the heap
00007f486d32b000 148 148 0 r---- libc-2.30.so
00007f486d350000 1332 888 0 r-x-- libc-2.30.so
00007f486d49d000 296 128 0 r---- libc-2.30.so
00007f486d4e7000 4 0 0 ----- libc-2.30.so
00007f486d4e8000 12 12 12 r---- libc-2.30.so
00007f486d4eb000 12 12 12 rw--- libc-2.30.so
00007f486d4ee000 24 24 24 rw--- [ anon ]
00007f486d52e000 8 8 0 r---- ld-2.30.so
00007f486d530000 124 124 0 r-x-- ld-2.30.so
00007f486d54f000 32 32 0 r---- ld-2.30.so
00007f486d558000 4 4 4 r---- ld-2.30.so
00007f486d559000 4 4 4 rw--- ld-2.30.so
00007f486d55a000 4 4 4 rw--- [ anon ]
00007ffc63ea8000 136 20 20 rw--- [ stack ]
00007ffc63f00000 12 0 0 r---- [ anon ]
00007ffc63f03000 4 4 0 r-x-- [ anon ]
ffffffffff600000 4 0 0 --x-- [ anon ]
---------------- ------- ------- -------
total kB 2496 1676 304
I have a lot to learn about the intricacies of measuring process memory usage, but I know that RSS represents memory that is held in RAM, and Kbytes is the total usage include virtual memory, paging etc.
The row at address 00005652b67a1000 is the heap (you can confirm this by
running pmap -X to see more verbose output):
00005652b67a1000 288 216 216 rw--- [ anon ]
Out of curiosity, if I run kilo without opening a file, the heap size is about 156KB smaller:
00005601d9ca8000 132 4 4 rw--- [ anon ]
Back on the version of kilo that has my example file open, if I invoke
history_push() and run my pmap script again, I just see the diff since last
time:
Address Kbytes RSS Dirty Mode Mapping
8c8
< 00005652b67a1000 288 216 216 rw--- [ anon ]
---
> 00005652b67a1000 420 400 400 rw--- [ anon ]
27c27
< total kB 2496 1676 304
---
> total kB 2628 1860 488 // +132, +184, +184
The only change is the heap size. My total heap memory has increased by 132K, and the RSS by 184K. That's not a great start considering my whole file is less than 29K.
Let's see what happens after a few more invocations of history_push(). Below
are the changes. Each row is a diff against the row above it:
| num calls | Heap Kbytes | Heap RSS |
|---|---|---|
| start | 288 | 216 |
| 1 | +132 | +184 |
| 2 | +288 | +188 |
| 3 | +132 | +192 |
| 4 | +132 | +192 |
| 5 | +312 | +192 |
| 10 | +836 (avg 167.2) | +956 (avg 191.2) |
| end | 2120 | 2120 |
So it looks like our RSS memory allocation increases consistently by 192KB with every state copy. The first couple of calls instead increase by 184 and 188 respectively, but I'm ignoring this as I think it's easily explainable by the editor behaviour. However, I do wonder why sometimes our total heap size increases by 132, and other times it's more.
10. Where is this memory going?
We can reason about some of this heap increase by looking at the size of our
data. Using sizeof() on our copied structs, I can see the following:
| type | size (bytes) |
|---|---|
| struct editorConfig | 232 |
| struct termios | 60 |
| struct erow | 48 |
We only make one copy of editorConfig and termios, so their footprint should
be negligible. However, although erow is only 48 bytes, a new erow is put on
the heap for each line in the file. There are 1056 lines, so (sizeof(erow) *
1056) immediately accounts for 50.6KB.
The char array for each row is stored in erow->chars. This stores all the text
in the file, and we know the sum of all erow->chars arrays should come to
about 29KB (because that's the file size). But there are two other char arrays
of approximately the same size: erow->render and erow->hl, which
respectively store a pretty-rendered version of the row and the syntax
highlighting data for the row. Taking these into account is 3 * 28.7 = ~86KB.
We can now account for roughly 135KB between the size of the erow struct, and
the contents of the erow arrays. I was initially expecting it might be close
to 192KB, as we see the 192KB increase consistently. 135KB doesn't exactly match
to anything, although it is close to the 132KB total memory increases that we see.
11. What about the other increases?
Why do we consistently see +192KB in RSS? I'm actually not sure without diving
into some more detailed profiling. There isn't any obvious new data being
allocated to the heap in the code. I ran a test where I disabled most of the
editor's code other than history_push(), and still saw this +192KB pattern. I
wonder if the copying logic makes the program move some other data that was
already allocated to memory into RSS.
I have no good ideas about the total memory heap increases that are higher than
132KB - I think the most likely explanation is that I need to run valgrind and
make sure I have no memory issues. I'm also curious why sometimes the total
heap memory and the RSS memory are the same size, but sometimes they're
different - that's a whole separate investigation though.
12. How can we make this feature more efficient?
I have a few questions about those memory numbers, but regardless we have some
useful information: each copy of history will cost a fixed 48 bytes per row for
the erow struct, and then an extra 3x the actual text size of the row (for
row->chars, row->render and row->hl respectively). For our example file,
that's ((1056 * 48bytes) + (28.7KB * 3)), which in total is about 135KB.
If I want to keep 50 of these revisions, it will cost at least ~6.75MB, and in practice it will be higher (as we have these unaccounted-for memory increases).
There are various ways we could try to reduce this cost. Some that immediately come to mind:
Stop storing the erow->render and erow->hl fields
…and instead just re-compute them on restore, as they can be completely recreated
from the erow->chars state. This is cheap to implement, and will reduce the
cost of storing the text data by 3x.
Don't store an erow struct at all in our undo state
All of the state in the erow can be recomputed based on the contents of
our text. Every erow struct costs 48 bytes, but in our example text
file, we average at 27.2 bytes per line. It would be cheaper to just store the
entire contents of the file and recreate the erows later based on the
text contents.
Shallow copy instead of deep copy
We're deep copying everything, even for parts of the buffer that don't change. This isn't necessary - we could just create pointers to rows that haven't changed. This could prevent a lot of duplicate storage.
Serialize and compress the state history
If we have to store the editor state, maybe we can make it smaller. Gzip can compress our example text file with ratios between 2.8:1 (quickest compression level) and 3.4:1 (slowest compression level). This is something that I could prototype in a few lines of Python or Go, but in C I'm not familiar with the ecosystem, so it might take some time to develop.
Compute a delta between different states
…and use it to recreate state on restore. This is a similar situation to serialization/compression for me - it's a lot more work to do this than to just write individual undo operations for the commands in the editor.
13. Rethink the generalised state-restore approach entirely?
Ultimately there are cases where all of these approaches can fall down, especially when dealing with very large files, or files with very long lines. There are also tradeoffs to make on whether we can compute the values that we're no longer storing in memory within a latency that's suitable for the user.
For any performance-conscious use case I think it will be more efficient to just store specific undo operations for each action that you want to undo - ie. follow the command pattern.
14. Next steps
I could have implemented shallow copy (as that sounds interesting), or even just written specific undo actions for all my editor operations.
Instead, I went on a massive tangent to see how Emacs, Vim and Nano implemented their undo features.